一、使用场景
Merge表有点类似于视图。使用Merge存储引擎实现MySQL分表,这种方法比较适合那些没有事先考虑分表,随着数据的增多,已经出现了数据查询慢的情况。
这个时候如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码。所以使用Merge存储引擎实现MySQL分表可以避免改代码。
Merge引擎下每一张表只有一个MRG文件。MRG里面存放着分表的关系,以及插入数据的方式。它就像是一个外壳,或者是连接池,数据存放在分表里面。
merge合并表的要求:
- 合并的表使用的必须是MyISAM引擎
- 表的结构必须一致,包括索引、字段类型、引擎和字符集
对于增删改查,直接操作总表即可。
二、建表
1.用户表
CREATE TABLE `user1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
2.用户表2
create table user2 like user1;
3.主表
CREATE TABLE `alluser` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
KEY `id` (`id`)
) ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8 INSERT_METHOD=LAST UNION=(`user1`,`user2`);
1) ENGINE = MERGE 和 ENGINE = MRG_MyISAM是一样的意思,都是代表使用的存储引擎是 Merge。
2) INSERT_METHOD,表示插入方式,取值可以是:0 和 1,0代表不允许插入,1代表可以插入;
3) FIRST插入到UNION中的第一个表,LAST插入到UNION中的最后一个表。
三、操作
1. 先在user1表中增加一条数据,然后再在user2表中增加一条数据,查看 alluser中的数据。
insert into user1(name,sex) values ('张三',1);
insert into user2(name,sex) values ('李四',2);
select * from alluser; 发现是刚刚插入的数据如下:
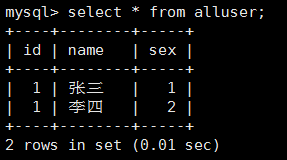
这就出现了一个id重复,这就造成了当删除和修改的时候异常,解决办法是给 alluser的id赋唯一值。
我们解决方法是,重新建立一张表tb_ids(id int),用来专门存一个id的,并插入一条初始数据,同时删除掉user1和user2中的数据。
create table tb_ids(id int);
insert into tb_ids values(1);
delete from user1;
delete from user2;
然后在user1和user2表中分别建立一个触发器(tr_seq和tr_seq2),触发器的功能是 当在user1或者user2表中增加一条记录时,取出tb_ids中的id值,赋给user1和user2的id,然后将tb_ids的id值加1,
user1表的触发器内容如下(user2表的触发器修要修改 触发器的名字 和 表名):
DELIMITER $$
CREATE TRIGGER tr_seq
BEFORE INSERT on user1
FOR EACH ROW BEGIN
select id into @testid from tb_ids limit 1;
update tb_ids set id = @testid + 1;
set new.id = @testid;
END$$
DELIMITER;
2.在user1和user2表中分别增加一条数据,
insert into user1(name,sex) values('王五',1);
insert into user2(name,sex) values('赵六',2);
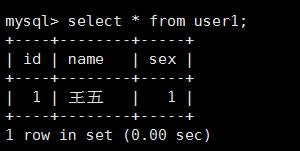
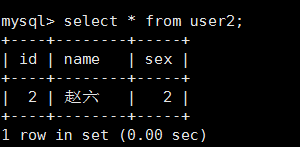
3.查询user1和user2中的数据:
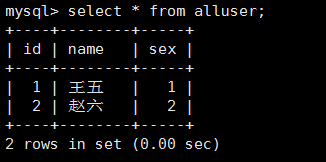
4.查询总表alluser中的数据,发现id没有重复的:
完成